
인덱싱을 하는 이유
업데이트:
- 테이블에 대한 검색 속도를 높이기 위해 생성하며 컬럼에 적용
- 주로 B-Tree 혹은 B+Tree 자료구조로 구현되는 것이 일반적
- 대규모 테이블에 대해 적용하며 삽입,수정,삭제가 자주 발생하지 않는 경우에 활용
- 인덱스가 있을 경우 검색 속도 증가
- 테이블에 없는 정보 검색 시 빠른 판단이 가능
Btrees는 이진 트리에서 발전된 구조
이진 트리란?
최대 두개의 자식 노드를 가지는 트리 자료구조
이진트리의 종류
- 정이진트리
트리의 모든 node가 0개 혹은 2개의 자식을 가지는 경우 - 포화이진트리
leaf node가 끝까지 정말 꽉찬 트리 - 완전이진트리
마지막 레벨을 제외한 모든 레벨에서 순서대로 node가 꽉채워진 트리 - 균형이진트리
leaf node들의 레벨차이가 최대 1레벨까지만 나는 트리
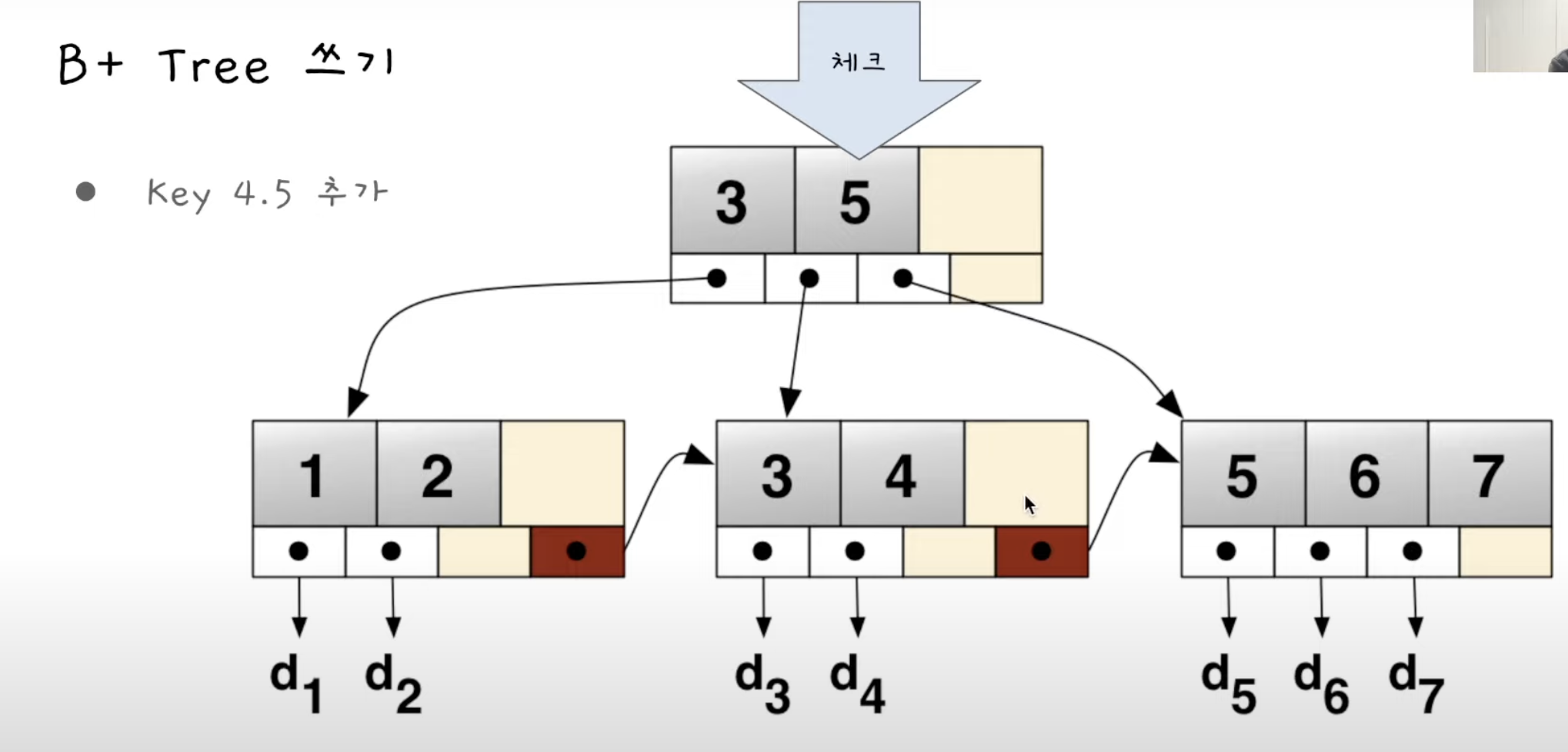
B+ Tree 구조(B-트리보다 읽는것은 빠름, 수정에서는 오버헤드)
- 이름처럼 트리 구조- 바이너리 트리랑 개념적으로 비슷함
- key 값으로 정렬되어 있음.- children 노드가 여러개임.
- 데이터는 리프노드에만 있음.
- 각각의 노드가 메모리가 아닌 디스크에 있음.
- 더 추가하다보면 Tree Depth가 늘어남.
- 대부분의 경우 3-4 Depth정도로 모든 데이터를 처리할 수 있음
- B+ Tree 쓰기는 여러 Disk Write가 필요할 때가 있음. -> 데이터 추가 쉽지 않음.
댓글남기기